第5章 ぱそこんであそぼ
72回生 湯浅太蔵
5.1 自己紹介などなど
おはようございますこんにちはこんばんは。72回生の湯浅太蔵と申します。本編にお越しいただいてありがとうございます。いつのまにか高校二年生になってしまいとてもつらいのですが、残り1.5年(?)の青春(?)を謳歌したいと思っております。
当たり前ですが高校生活を送ることができる時間は限られています。なので、日々の煩わしい作業を目の前の優秀なパソコンくんに任せてしまおうと考えました。というわけで、作業の自動化をテーマに部誌を進めていきます。
この記事では、Pythonというプログラミング言語を使用します。特徴としては、
- 必要に応じてモジュールというものを利用できる
- インデント(行頭の空白)自体に意味が持たせられていて、ソースコードが読みやすい(逆に言えば、インデントを間違えると実行できない)
等が挙げられます。
ちなみに、Pythonという名前の由来は、イギリスのコメディグループであるモンティ・パイソンらしいです。
モジュール・パッケージ
Pythonにおいてモジュールとは、他のファイルから読み込んでその機能を使うことができるファイルのことです。モジュールを作っておけば、同じプログラムを何度も書く手間が省けます。
また、パッケージは、様々なモジュールがひとまとめになったものです。
モジュールを読み込むには、ファイルの先頭に import モジュール名 と記述します。
5.2 環境構築
本題に入る前に、まずパソコンでPythonを実行できる環境を作りましょう。
Pythonのホームページからインストールしてもよいのですが、様々なライブラリやツールが付属しているAnacondaをインストールするほうが便利です。
https://www.anaconda.com/download/
ホームページからAnacondaをインストールしましょう。2ではなく3の方をインストールします。(Python2系はしばらくするとサポートが打ち切られてしまうため)
特に理由がなければ、そのままの設定でインストールしましょう。
macOSやLinux,Windows Subsystem for Linuxを利用している方は、コマンドを使ってインストールするほうが簡単です。
Linux
sudo apt-get install python3 python3-pip
pipはPython用のパッケージ管理システムです。
macOS
HomebrewというmacOS用のパッケージマネージャからインストールします。
Homebrewのインストール
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Pythonのインストール
brew install python3
5.3 Pythonのプログラムを実行する
Pythonをのプログラムを実行するには、インタラクティブシェルを利用する方法と、ファイルを実行する方法があります。
インタラクティブシェル
コマンドラインに Python3 または Python と入力すると、インタラクティブシェル(対話型シェル)が立ち上がります。
インタラクティブシェルには、以下のように、直接プログラムを打ち込むことが出来ます。
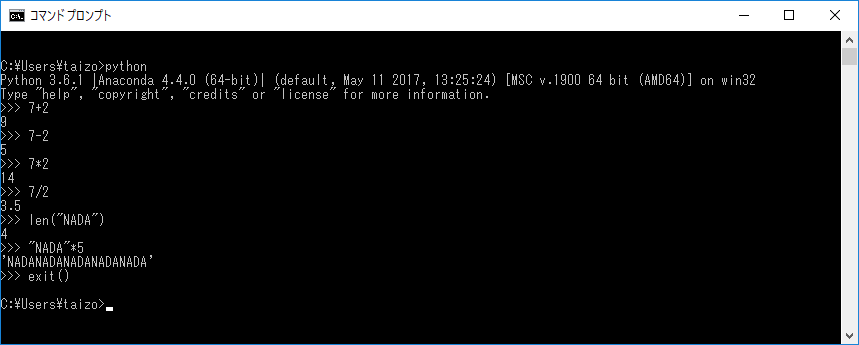
ファイルを実行
インタラクティブシェルは簡単なプログラムを実行するのには向いていますが、複雑なプログラムを処理するにはファイルごと実行する必要があります。
python(または python3) ファイル名 と入力すれば、ファイルを実行できます。
Helloworld.py
print('Hello,world!')
C:\Users\taizo>python Helloworld.py Hello,world!
5.4 プログラムからパソコンにアクセス
osというモジュールを使えば、Pythonのプログラムからパソコンの状態を見ることができます。
簡単な例として、指定したディレクトリの中から、指定した拡張子のファイルを表示するプログラムを作ってみます。
FindFile.py
1 2 3 4 5 6 7 8 9 10 11 12 13 | #! python3 # -*- coding: utf-8 -*- import os import sys folder = sys.argv[1] extension = sys.argv[2] #folder以下の拡張子がextensionのファイルを探す for foldername, subfolders, filenames in os.walk(folder): for filename in filenames: if filename.lower().endswith(extension):#ファイル名を小文字に変換→ファイル名の末尾がextensionであるファイルを表示 print(os.path.join(foldername, filename))#見つけたファイルの絶対パスを表示 |
- 最初の2行
最初の行はマジックコメントと呼ばれ、実行するPythonのバージョンと、プログラムの文字エンコーディングを示しています。
sys
sysモジュールをimportすると、プログラムに引数を渡すことができるようになります。引数はsys.argvに格納されます。たとえば、
argv.py
1 2 3 | import sys for i in sys.argv: print(i) |
これはすべての引数を表示するプログラムですが、これを実行すると、
C:\Users\taizo>python argv.py a b c argv.py a b c
となります。sys.argv配列の一つ目にはファイル名が入ることになっています。
os.walk
指定したフォルダの中を渡り歩いてくれる関数です。for文で呼び出すと、繰り返しごとに、
- 現在のフォルダ名を表す文字列
- 現在のフォルダの中にあるフォルダ名を表す文字列のリスト
- 現在のフォルダの中にあるファイル名を表す文字列のリスト
の3つの値を返します。
os.path.join
パスの区切り文字はOSによって異なりますが、この関数にフォルダ名とファイル名を渡すと、適切な区切り文字でパスを作ってくれます。
12~13行目では、os.walk関数によって見つけたファイルのうち、末尾がextension(つまり拡張子がextension)のファイルが有れば、その絶対パスを表示する、ということをしています。lower関数は文字列を全て小文字にするものですが、拡張子が大文字の可能性も考慮して使っています。
Cドライブからjpg画像を探すときは以下のようにします。
python (FindFile.pyの絶対パス) C:// jpg
絶対パスと相対パス
今、C:\Usersを見ているします。C:\Users直下にnpca.pngというファイルがあるとすると、相対パスはnpca.png、絶対パスはc:\Users\npca.pngとなります。このように、今見ているファイルからの相対的な位置を示すのが相対パス、今どこを見ているかに関係なくファイルの位置を示すのが絶対パスです。
5.5 Webから情報を取得する
今、Web上には情報が溢れています。その大量の情報の中から、自分に必要なものだけを集めるという作業は、様々なことに活用できます。
クローリング&スクレイピング
先に用語の解説をしておきます。
- クローリング
- Web上の情報を集めることをクローリング(Crawling)といいます。クローリングを行うプログラムはクローラーと呼ばれます。
- スクレイピング
- クローリングして集めてきた情報から必要なものを抜き出していく作業をスクレイピング(Scraping)といいます。
クローラーは、Googleの検索エンジンなど、私達の身近なところで用いられています。自分好みのクローラーを作れば、役に立つこと間違いなしです。
ここでは、朝天気予報を見るのが億劫なので、https://tenki.jpという天気予報のサイトで日中の降水確率を取得し、特定の割合より高ければメールでお知らせする、というツールを作ってみます。
目覚まし時計としてスマホを使っていれば朝必ずスマホを確認するので、天気予報のメールを送信して、スマホの通知でそれを確認することにします。
天気予報メール
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | #! python3 # -*- coding: utf-8 -*- import requests import bs4 import smtplib from email.mime.text import MIMEText from email.header import Header percent = 70 # 降水確率がpercentより高ければ雨の通知 url = requests.get('https://tenki.jp/forecast/6/31/6310/28100/') # 変数urlに指定したURLをダウンロード parse = bs4.BeautifulSoup(url.text, "lxml") # 変数parseにurlを解析して入れる lxmlはHTMLのパーサー probability = parse.select('.rain-probability')[0] if int(probability.select('td')[1].text[0]) >= percent or int(probability.select('td')[2].text[0]) >= percent: letter = '今日は雨です' else: letter = '今日は傘は要りません' charset = 'iso-2022-jp' message = MIMEText(letter, 'plain', charset) message['Subject'] = Header('セルフ天気予報'.encode(charset), charset) smtp_obj = smtplib.SMTP('smtp.gmail.com', 587) smtp_obj.ehlo() smtp_obj.starttls() smtp_obj.login('FROM', 'PASSWORD') smtp_obj.sendmail('FROM', 'TO', message.as_string()) smtp_obj.quit() |
12~15行目でHTMLの解析、20~28行目でメールの送信をしています。
requestsモジュール
webからファイルをダウンロードするためのモジュールです。
requests.get
指定したURLをダウンロードする関数です。
bs4モジュール
bs4の正式名称はBeautifulSoup4です。BeautifulSoup4はHTMLを解析するためのモジュールです。
bs4.BeautifulSoup
指定したHTMLを解析(パース)します。lxmlはHTMLのパーサーのひとつです(pip install lxml する必要があります)。
smtplibモジュール
メールを送信するのに必要なモジュールです。SMTP(Simple Mail Transfer Protocol)は、メールを送信するためのプロトコルです。
smtplib.SMTP
メールサーバーに接続するための関数です。smptサーバー名とポート番号を指定する必要がありますが、ここでは、Gmailのsmtpサーバーと、コマンドを暗号化するための規格TLSを使う587番を指定しています。
smtplib.ehlo、smtp_obj.starttls、smtp_obj.quit
サーバーとの接続を確立する関数、TLS通信を利用するための関数、サーバーから切断するための関数です。
smtp_obj.login
メールを送信する際の、メールアドレスとパスワードを指定します。このとき、Googleで、アプリケーション固有のパスワードを設定する必要があるかもしれません。https://support.google.com/accounts/answer/185833から詳しい説明を見ることが出来ます。
smtp_obj.sendmail
FROMに送信側のメールアドレス、TOに受信側のメールアドレスを指定します。最後にメッセージを入力します。
MIMEText、Header、as_string
日本語のメールを送るために必要な関数です。本文にはMIMEText関数、ヘッダーにはHeader関数を利用します。
12~15行目のHTMLの解析について説明します。
tenki.jpは以下のような構成になっていますが、取得したいのは丸で囲んだ部分です。
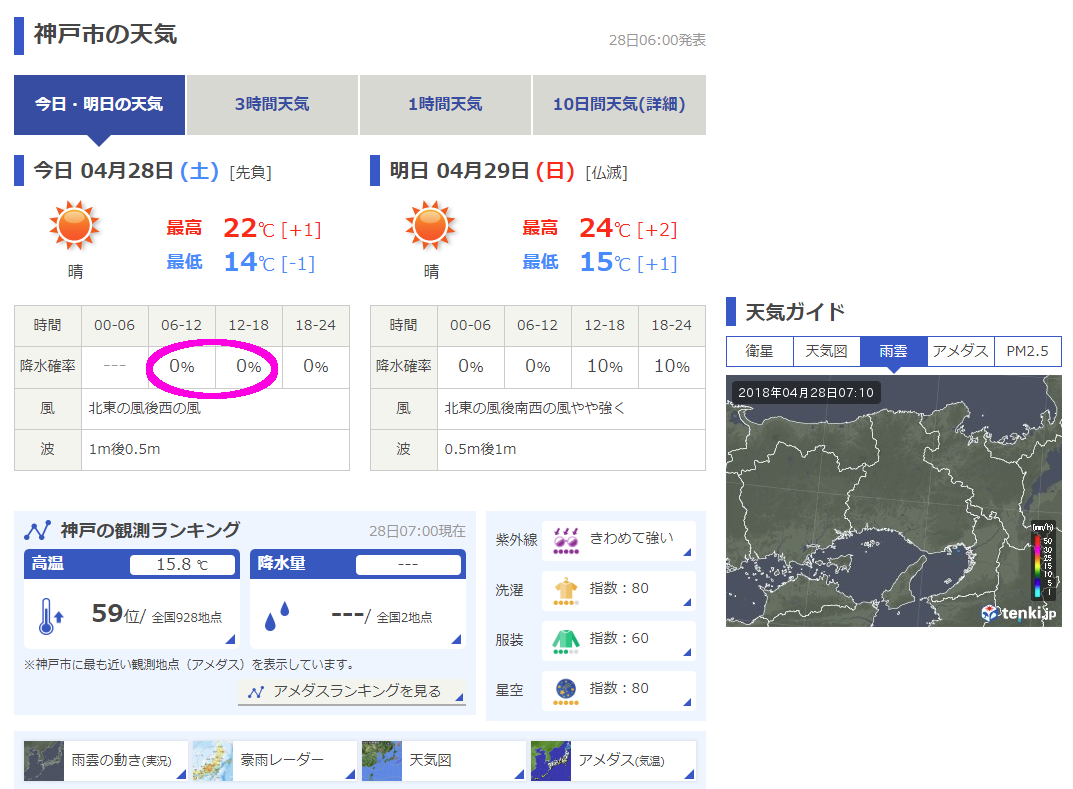
図: tenki.jpの神戸市のページ
ページのソースを見ると(このメニューは右クリックやCtrl+Uで開けます)、取得したい部分はrain-probabilityというクラス名を持っていることがわかるので、select関数で指定します(.〇〇とすると、「クラス名が〇〇」と指定することになります)。

図: tenki.jpのソース
rain-probabilityは2つありますが、取得したいのは当日の予報なので1つめを指定して、更にその中の4つのtd要素のうち通学時間に関係のある2つめと3つめを指定します。またまたさらに、td要素は数値と'%'という文字を要素に持っているので、そのうちの数値を指定します。
こうして取得した2つの数値(6~12時の降水確率と12~18時の降水確率)が変数percentの値より大きいか小さいかによってメールの本文を変えています。
あとは、このプログラムを朝7時くらいに自動で実行するようにしておけば、セルフ天気予報の完成です。
Windowsにはタスクスケジューラがあるので、それを使います。
.pyファイルは直接実行するだけではうまく動きません。なので、「.pyファイルを実行する」というバッチファイルを作る必要があります。以下のようにします。
@(python.exeの絶対パス) (プログラムの絶対パス) %*
このバッチファイルを自動実行するようにすればOKです。
API
API(Application Programming Interface)とは、ソフトウェアコンポーネントが互いにやりとりするのに使用するインタフェースの仕様である。(Wikipediaより)
難しいですね。簡単に言えば、ソフトウェアの機能の一部を公開して、他のソフトウェアから利用できるようにしたものです。
APIを公開しているサービスはいろいろありますが、ここではTwitterとYouTubeを扱います。
Twitter API
Twitterについて今更説明する必要はないかもしれませんが、TwitterはSNSの一種です。APIを利用すれば、タイムラインや特定のアカウントのツイートなどを取得することが出来ます。
公式のリファレンスは以下のURLです。
https://developer.twitter.com/
Twitter APIの認証
Twitter APIは、利用する前に認証を受ける必要があります。
Twitterの認証情報を取得するためには、最初にアプリケーションを登録する必要があります。アプリケーションの管理画面(https://apps.twitter.com/)ログインし、「Create New App」ボタンをクリックするとアプリケーションの作成画面が表示されます。データ収集が目的の場合は「Callback URL」に入力する必要はありません。
アプリケーション作成後「Keys and Access Tokens」タブでキーを確認できます。「Create my access token」でアクセストークンを生成しておきます。
画像を集める
どんなツールがあれば便利かと考えてみた結果、ツイートに含まれる画像だけをダウンロードするものを作ることにしました。
好きな俳優やアイドルやイラストレーターが居るとして、その可愛い写真やかっこいい写真が一瞬で手に入ればとっても楽ですよね。ということで、特定のアカウントのうち、画像ツイートを検出して、その画像をダウンロードする、というツールを作ることにします。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | #!python3 # -*- coding: utf-8 -*- from requests_oauthlib import OAuth1Session import os import time import shelve import requests file = shelve.open('lasttweet') lasttweet = file['lasttweet'] # 最後にチェックした日付 CONSUMER_KEY = os.environ['KEY'] CONSUMER_SECRET = os.environ['SECRET'] ACCESS_TOKEN = os.environ['ACCESS_TOKEN'] ACCESS_TOKEN_SECRET = os.environ['ACCESS_TOKEN_SECRET'] twitter = OAuth1Session(CONSUMER_KEY, client_secret=CONSUMER_SECRET, resource_owner_key=ACCESS_TOKEN, resource_owner_secret=ACCESS_TOKEN_SECRET) response = twitter.get('https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name=@@@@@&since_id=' + lasttweet + '&count=300&exclude_replies=true&include_rts=false') for tweet in response.json(): try: for image in tweet['extended_entities']['media']: image_url = image['media_url'] print(image_url) image = requests.get(image_url) image.raise_for_status() image_file = open(os.path.join('画像を保存したいフォルダの絶対パス', os.path.basename(image_url)), 'wb') for chunk in image.iter_content(100000): image_file.write(chunk) image_file.close() time.sleep(5) except: pass file.close() |
Twitterの認証を得た後、22行目で特定のユーザーのツイートを取得し、24~37行目で、ツイートの中から画像を探してダウンロードしています。
from requests_oauthlib import OAuth1Session
Twitter APIではOAuth認証を用いています。このモジュールはOAuth認証を確認するのに必要なものです。
shelve
shelveモジュールはプログラム内の変数の値をバイナリ形式で保存しておくためのものです。shelveは、Pythonの辞書型のように扱うことが出来ます。このプログラムではチェックした最後のツイートのIDを'lasttweet'というキーに保存しています。
openでファイルを開き、closeでファイルを閉じます。
このプログラムを実行する前に、'lasttweet'の値を設定しておく必要があります。
import shelve file = shelve.open('lasttweet') file['lasttweet'] = '〇〇' file.close()
このようなプログラムで値を設定できます。
- 認証キー
Twitterのアプリケーション画面で確認したキーを入力するのですが、プログラムに直接書くと、ネット上にアップしてしまう可能性などが有り危険です。環境変数に登録しておき、os.environで参照するようにすると安全です。
- 22行目
22行目では、条件に合致するツイートをjson形式で入手しています。
表5.1:
| 名前 | 機能 |
|---|---|
screen_name | ツイートを取得したいユーザー名(@以下の文字列)を指定する |
since_id | 指定したIDより未来のツイートを取得する |
count | 指定した数のツイートを取得する |
exclude_replies | trueを指定すると、リプライを除外する |
include_rts | falseを指定すると、リツイートを除外する |
- 24~37行目
ここでは、画像つきツイートを検出し、さらに画像を抜き出して保存するという作業をしています。try~except文は、try以下のプログラムが実行できる場合は実行し、出来ない場合はexcept以下のプログラムを実行するという構文なので、ツイートに画像が含まれていればtry以下が実行されます。
取得したツイートは、json形式で以下の画像のようになっています。
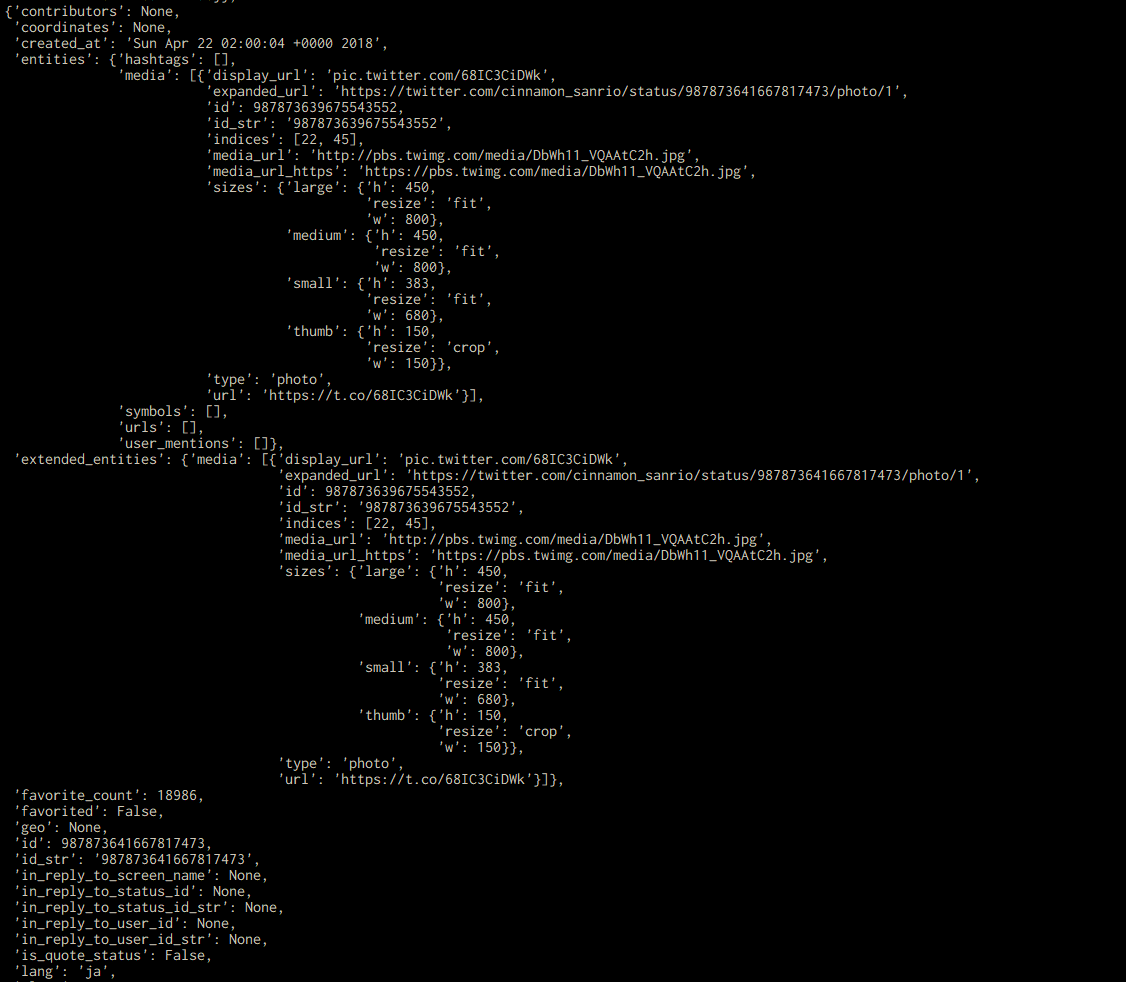
これを見ると、ツイートに含まれる画像のURLはextended_entitiesの中の、mediaの中の、media_urlというところにあることがわかります。
29~34行目で画像を保存しています。
raise_for_statusとしておくと、エラーが起こった場合にプログラムを終了させられます。
31=33行目では、画像ファイルを作成し、バイナリ書き込み形式で開き、100000バイトごとに書き込むという作業をしています。
書き込みが終了したらファイルを閉じ、その後、5秒間の待ち時間を設けています。これは、連続でダウンロードするとサーバーに負荷がかかるためです。
ということで、シナモンのアカウントで実際に実行してみます。
かわいい(小並感)。
YouTube API
YouTubeも説明する必要はないと思いますが、Googleが作った動画サイトです。APIを使えば、ユーザーのアップロードした動画や、登録チャンネルの情報などを取得出来ます。
公式のリファレンスは以下のURLです。
https://developers.google.com/youtube/v3/?hl=ja/
YouTube APIの認証
YouTubeAPIも、利用する前に認証を受ける必要があります。
Google API Console(https://console.developers.google.com)にログインし、新規プロジェクトを作成します。その後、「APIとサービスの有効化」から「YouTube Data API v3」を有効にします。さらに、「認証情報」からAPIキーを作成すれば、準備は完了です。
登録チャンネルの未視聴の動画を開く
僕はYouTubeでは、特定のジャンルの動画を見るというよりも、登録チャンネルの動画の方をよく見るのですが、自分の登録チャンネルのページへ行っていちいち動画を開くのが面倒なので、ブラウザで一気に開いてくれるツールを作ることにします。
なお、事前にhttps://www.youtube.com/account_privacyから登録チャンネルを公開するようにしておかないと、登録チャンネルの情報にアクセスできない可能性があります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | from apiclient.discovery import build import webbrowser import datetime import shelve import os file = shelve.open('begintime') begindate = datetime.datetime(int(file['year']), int(file['month']), int(file['day']), nt(file['hour']), int(file['minute']), int(file['second'])) nowdate = datetime.datetime.now() youtube = build('youtube','v3',developerKey=os.environ['GOOGLE_KEY']) search = youtube.subscriptions().list(part='snippet', channelId='ID').execute() def getchannel(info): for channel in info['items']: getmovie(channel['snippet']['resourceId']['channelId']) if('nextPageToken' in info.keys()): nextpage = youtube.subscriptions().list(part='snippet', channelId='ID', pageToken = info['nextPageToken']).execute() channelname(nextpage) def getmovie(info): channel = youtube.channels().list(part='contentDetails', id=info).execute() uploads = youtube.playlistItems().list(part='snippet', playlistId=channel['items'][0]['contentDetails']['relatedPlaylists']['uploads'], maxResults=50).execute() for movie in uploads['items']: moviedate = datetime.datetime.strptime(movie['snippet']['publishedAt'], '%Y-%m-%dT%H:%M:%S.000Z') moviedate += datetime.timedelta(hours=9) if moviedate > begindate: webbrowser.open('https://www.youtube.com/watch?v=' + movie['snippet']['resourceId']['videoId']) getchannel(search) file['year'] = nowdate.year file['month'] = nowdate.month file['day'] = nowdate.day file['hour'] = nowdate.hour file['minute'] = nowdate.minute file['second'] = nowdate.second file.close() |
初めに自分のアカウントの登録チャンネルの情報を取得しています。次に、各登録チャンネルからアップロード動画の再生リストを取得し、その中の動画で、チェックしていないものをブラウザで開いています。
from apiclient.discovery import build
Pythonには、Google API Client for Pythonという、Google APIで共通して使えるモジュールがあります。事前にpip install google-api-python-clientしておく必要があります。
webbrowserモジュール
URLをブラウザで開くのに使います。
datetimeモジュール
日付の計算などに使います。datetimeモジュールには、datetimeという独自のデータ型があり、year、month、day、hour、minute、second、microsecondという属性を持ちます。shelveを用いて、最後にチェックした日時を保存しています。shelveを使うので、先程と同じように最初に値を設定しておく必要があります。
- YouTube APIの仕様
最初にYouTubeのAPIクライアントを組み立てる必要があります。10行目のbuild関数でそれを行っていて、第一引数にAPI名、第二引数にバージョン名、第三引数に先程取得したAPIキーを入力します。
登録チャンネルの情報を取得するには、subscriptions().listリソースにアクセスします。partには取得する情報の形式を、channelIdには自分のチャンネルのIDを入力します。(YouTubeのチャンネルのURLは https://www.youtube.com/channel/〇〇 となっていますが、IDはchannel以下の〇〇部分のことを指します。)
そして、execute()を実行することで、json型のデータが取得できます。
getchannel関数では、先程取得したデータから、登録しているチャンネルのURLを抽出しています。subscriptions().listで取得したデータには、items要素の中に、1ページに5個ずつチャンネルに関する情報が載っています。6個以上のチャンネルを取得した場合、nextPageTokenの値をsubscriptions().listのpageToken属性で指定することで、2ページ目以降にもアクセスできます。引数として、登録しているチャンネルのIDをgetmovie関数に渡しています。
getmovie関数では、動画の日付を取得し、チェックしていない新しい動画があればその動画を開いています。
channels.list()リソースにアクセスすることで、特定のチャンネルの情報を取得できます。partには取得する情報の形式を、idにはチャンネルのIDを入力します。
各チャンネルの情報は以下のようになっていて、itemsの中の、contentDetailsの中の、relatedPlaylistsの中の、uploadsにアップロード動画の再生リストのIDがあります。
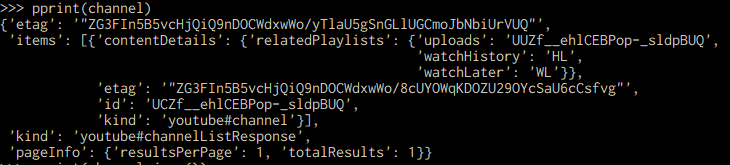
playlistItems().listリソースにアクセスすることで、プレイリストに関する情報を取得できます。partには取得する情報の形式を、playlistIdにはプレイリストのIDを、maxResultsには1ページに表示する情報の最大数を入力します。
各動画の情報は以下のようになっていて、itemsの中の、snippetの中の、publishedAtに動画がアップロードされた日時があります。
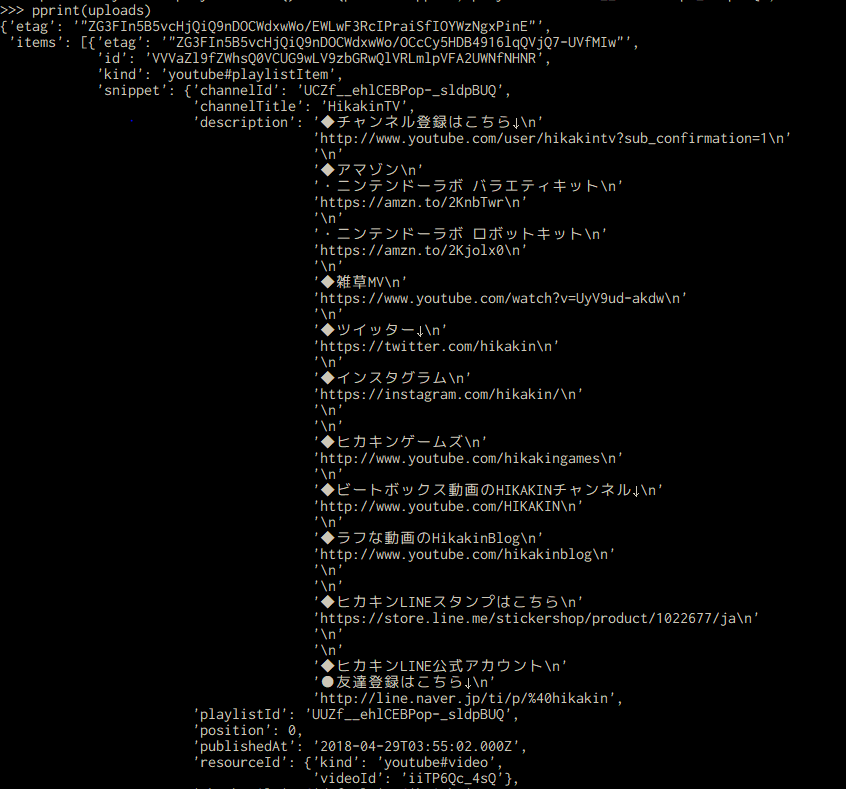
ただし、その日時は(2018-04-28T10:51:56.000Z)このような形式で記述されていて、直接datetime型として使うことは出来ません。なので、datetimeモジュールに付属しているstrptime関数を用いてdatetime型に変換しています。
さらに、ここで取得できる日時は協定世界時で、日本時間より9時間遅いので、9時間足して上げる必要があります。
そして、最後にチェックした日時と動画がアップロードされた日時を比較して、動画がアップロードされた日時のほうが後であれば動画を開いています。
最後に、shelveのデータを更新して、ファイルを閉じて終了です。
それでは恒例(?)の、お披露目タイムといきましょう!

図:
最新の動画がたくさん開いていますね。成功です!(登録チャンネルが若干バレたけど別にいいや)
5.6 さいごに
気づいたらほとんどWeb関連の話になってしまいました。すみません。
もちろん、ここで全ての機能が紹介できるわけではないので、本文中のリファレンスなどを参照して、自分好みに改造してみてください。
ちょっとしたプログラムを組めば、面倒な作業がすぐに終わるということがわかっていただけたと思います。
プログラミングはすごいサービスを開発したり、壮大なゲームを作ったりするためのものだというイメージもありますが、このような身近なことにも活用できるということがわかってもらえれば嬉しいです。
この記事が少しでも皆様の役に立てば幸いです。
5.7 参考文献
Al Sweigart 著、相川愛三 訳(2017)「退屈なことはPythonにやらせよう――ノンプログラマーにもできる自動化処理プログラミング」オライリー・ジャパン
加藤耕太 著(2016)「Pythonクローリング&スクレイピング―データ収集・解析のための実践開発ガイド―」技術評論社
Twitter API 公式リファレンス https://developer.twitter.com/
YouTube API 公式リファレンス https://developers.google.com/youtube/v3/?hl=ja/